
Facial Keypoint Detection 😀
This project focuses on using computer vision to detect facial keypoints of a person from an image. The corresponding Kaggle Competition is called Facial Keypoint Detections. I develop a CNN model that can detect the facial keypoints accurately.
Important Files
load-analyze-dataset.ipynb: Explores, downloads, views, and creates the dataset for model training.train-models.ipynb: Train the CNN model and view loss plot and model performance on testbaseline_model.py: CNN model definitionaugmentation_cstm.py: Data augmentation methodsdata_cstm.py: Custom PyTorch Dataset and DataLoader for this dataset
Data Preparation
Our images are 29x29 grayscale images (1 channel). This makes training easier, faster and requires less computation. We are predicting 15 keypoints (x,y) on each image - a total of 30 points.
While preprocessing our data, we add data augmentation methods to allow the model to generalize on various images and distortions. I implemented the following augmentations:
- Horizontal Flip
- Linear Contrast
- Gaussian Blur
- Rotation
- Scaling
Our final dataset overlayed with the keypoints looks something like this.

Model Training
Here is the model archeciture I used, which has performed well.
BaselineNet(
(conv1): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=same)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=same)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=same)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=same)
(pool4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=same)
(pool5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc6): Linear(in_features=2304, out_features=1024, bias=True)
(drop6): Dropout(p=0.4, inplace=False)
(fc7): Linear(in_features=1024, out_features=512, bias=True)
(drop7): Dropout(p=0.4, inplace=False)
(fc8): Linear(in_features=512, out_features=30, bias=True)
)
Below is the loss plot for this model after training it for 100 epochs.
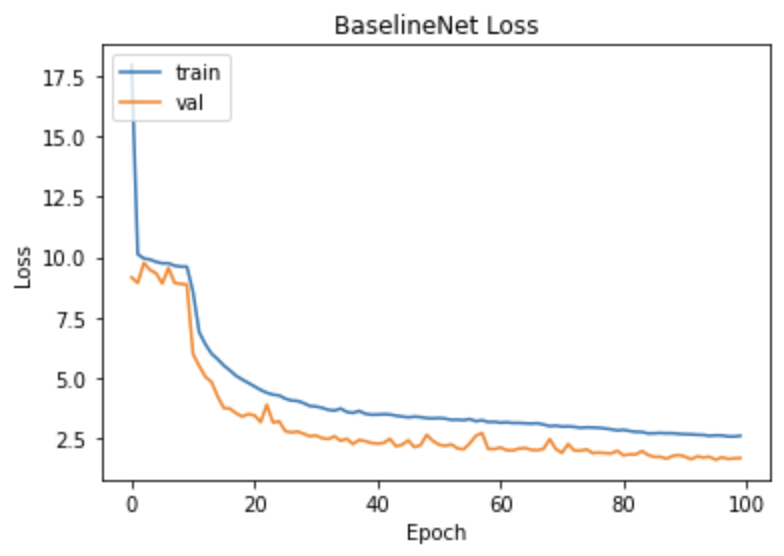
I had to stop the model training after 100 epochs due to the computational limits of my personal computer. But based on the plot, the loss is still decreasing after 100 epochs and should be trained for >100 epochs.
After 100 epochs of training, the model results on the test data are below.

We notice that the model is doing a pretty good job of predicting the keypoints in the correct areas of the face!